Advertisement
Image-to-image generation is one of the more interesting areas in artificial intelligence. It involves transforming a source image into a new image while keeping its overall structure intact. One approach that stands out is the use of depth2img models, which integrate depth perception into the process.
These models understand not just colors and outlines but also the spatial layout of a scene. That added depth of awareness allows for more coherent and realistic transformations. Pre-trained depth2img models make this process more accessible by reducing the need for training from scratch, offering a quicker path to usable results.
Image-to-image generation converts one type of image into another—sketches to photos, daylight to night scenes, or summer to winter. While most approaches rely on surface-level visual information, depth2img models introduce depth as a guiding factor. A depth map reflects how far each part of an image is from the viewer, which helps the model understand the structure and relationships between elements in a scene.
By incorporating depth, these models produce images that are more logically arranged. They avoid distortions common in standard image generation methods, especially when handling complex scenes. Whether it’s changing lighting or weather conditions, the presence of depth keeps objects in the right place and proportion.
Most depth2img models are based on diffusion networks. These models start with random noise and gradually refine it into a new image, guided by both the original image and its depth map. Because these models are pre-trained on large datasets, they can handle a wide range of inputs and produce realistic results without needing fine-tuning for every task.
Unlike text-to-image systems, which rely heavily on language prompts, depth2img focuses on spatial structure. This leads to more consistent outcomes, especially in cases where visual alignment matters more than creative interpretation.
The process starts with creating a depth map from the original image. This map identifies which parts are closer and which are farther, serving as a guide for the generative model. That depth input ensures the output image respects the original scene’s layout.

In diffusion-based systems, the model begins with noise and slowly generates the final image. At each step, it refers to both the depth and visual cues. This repeated reference helps maintain spatial consistency, keeping object shapes and positions realistic.
Pre-trained models are especially useful because they've already learned common depth-image patterns. They don't need to be retrained from the ground up, which reduces time and hardware demands. You can use them directly for tasks like style changes, lighting adjustments, or environmental transformations.
These models are particularly effective when the goal is to maintain the integrity of a scene. They excel at transformations where keeping spatial accuracy is important—such as turning a sunset photo into a midday version or adding snow to a landscape—without warping the underlying structure.
One of their strengths is that they don't require detailed user prompts. The depth of information itself provides a strong foundation for accurate scene interpretation. That makes them more user-friendly for tasks where realism is the priority.
depth2img pre-trained models have practical value across various fields. In creative industries, they allow artists and designers to take simple inputs and produce detailed variations—changing seasons, lighting, or mood—without redrawing the scene.
In architecture and planning, these models help visualize how structures would appear under different conditions. A building design can be rendered as if it were in sunlight, fog, or rain while maintaining its original shape and layout. The use of depth helps ensure the output remains grounded in the original design.
They also have potential in autonomous driving research. By generating varied scenes from a small set of originals, researchers can simulate rare driving scenarios, which helps improve training data for vehicle perception systems.
However, these models have their limitations. Scenes with low-depth variation or very flat geometry can challenge the system's ability to generate convincing results. While pre-trained models are efficient, they may not always perform well on niche content like medical images or aerial views, where specific knowledge is required. In such cases, some fine-tuning may still be necessary.
Another tradeoff is that while these models give more control over scene structure, they allow less freedom for abstract creativity. That makes them better suited for realistic transformations than for producing surreal or imaginative visuals, where spatial rules might be bent or broken.
Hardware requirements are another factor. Although using a pre-trained model is faster than training one from scratch, the process still requires decent computing resources, especially for high-resolution outputs or when processing a large number of images.
depth2img models reflect a broader trend in AI: building systems that don’t just manipulate images but understand the structure behind them. By adding a spatial layer to visual data, these models generate outputs that align more closely with how we see the world.

That shift makes a significant difference in areas such as editing, simulation, and storytelling. Instead of just recoloring an image or adding artistic filters, the AI can now adjust images while respecting the layout of the scene. It's a more grounded way of working with visuals.
These structure-aware models are changing the way visual tools function. Whether it’s in personal apps, creative software, or simulation platforms, the ability to preserve geometry while changing visual features is proving useful.
As development continues, we're likely to see more models that include depth or other structural cues. They'll be used in tools where realistic transformation is crucial, such as urban planning, scene restoration, or historical reconstructions. These systems won't just generate images—they'll generate them with a clearer grasp of how everything fits together.
depth2img pre-trained models add depth perception to image generation, helping produce more accurate and structured results. By utilizing spatial information, they preserve the layout of scenes during transformations such as lighting or seasonal changes. While they may not suit abstract creativity, their strength lies in realistic editing. As generative AI develops, depth-aware models are likely to be central in applications where visual accuracy and structure matter most.
Advertisement

How Vision Transformers (ViT) are reshaping computer vision by moving beyond traditional CNNs. Learn how this transformer-based model works, its benefits, and why it’s becoming essential in image processing

Lensa AI’s viral portraits raise concerns over user privacy, data consent, digital identity, representation, and ethical AI usage

Salesforce advances secure, private generative AI to boost enterprise productivity and data protection

Google Cloud’s new AI tools enhance productivity, automate processes, and empower all business users across various industries

Explore key Alibaba Cloud challenges and understand why this AI cloud vendor faces hurdles in global growth and enterprise adoption.

Celonis faces rising competition by evolving process mining with real-time insights, integration, and user-friendly automation

How Google Bard’s latest advancements significantly improve its logic and reasoning abilities, making it smarter and more effective in handling complex conversations and tasks
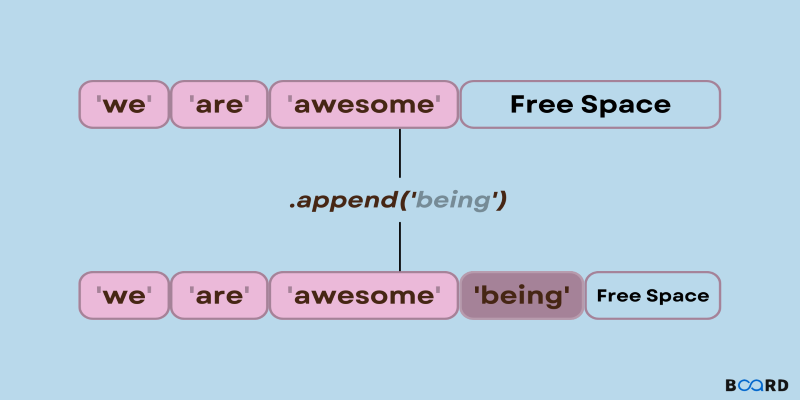
Need to add items to a Python list? Learn how append() works, what it does under the hood, and when to use it with confidence
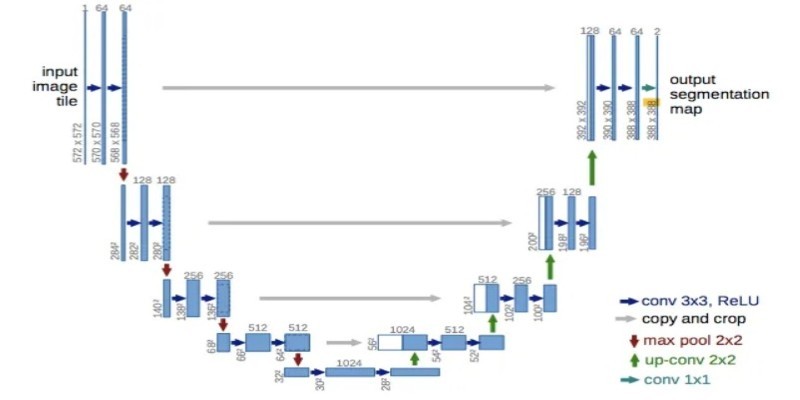
How UNet simplifies complex tasks in image processing. This guide explains UNet architecture and its role in accurate image segmentation using real-world examples

Master GPT-4.1 prompting with this detailed guide. Learn techniques, tips, and FAQs to improve your AI prompts

Discover how Cerebras’ AI supercomputer outperforms rivals with wafer-scale design, low power use, and easy model deployment

Find how AI is transforming the CPG sector with powerful applications in marketing, supply chain, and product innovation.